0-1搭建個性化推薦系統的設計思路
編輯導語:個性化推薦系統是互聯網和電子商務發展的產物,它是建立在海量數據挖掘基礎上的一種高級商務智能平臺,向顧客提供個性化的信息服務和決策支持。今天,本文作者就結合自己的經歷,為我們分享了從0到1搭建個性化推薦系統的設計思路。

1. 設計目的
- 商城已上線2周年,已有10萬+在售物品。需要推薦系統,幫助用戶從過量的物品中,快速發現優質物品,縮短用戶路徑,提高訂單量。
- 目前商城訂單量、用戶數增長緩慢,所以需要推薦系統,作為新的增長點,帶動業務增長。
- 通過全面采集用戶、物品數據,并分析各類用戶對各類物品的喜好,可以幫助商家快速了解平臺內用戶喜好,了解自己的物品特點,提高訂單量。
2. 產品結構

3. 推薦模型設計
3.1 基于物品的協同推薦
3.1.1 算法原理

基于物品的協同推薦算法認為: 當用戶A喜歡物品a,且物品a和物品b相似,則認為用戶A喜歡物品b。 所以搭建該算法分為兩步:
- 計算用戶A對物品a的喜愛度
- 計算物品a和物品b的相似度
用戶A對物品b的喜好矩陣=用戶A對物品a的喜好矩陣+物品a和物品b的相似度。
3.1.2 明確用戶的喜愛特征的權重
根據和業務專家的初步討論,明確用戶對物品的喜愛度,與以下行為有關:
- 瀏覽:用戶進入物品詳情頁后,在詳情頁停留的時長超過5S;
- 收藏:用戶點擊收藏按鈕,收藏了物品,且未取消收藏;
- 下單:用戶購買過該物品,且未退貨;
- 轉發:用戶轉發過該物品。
根據上述維度,可構建判斷矩陣:
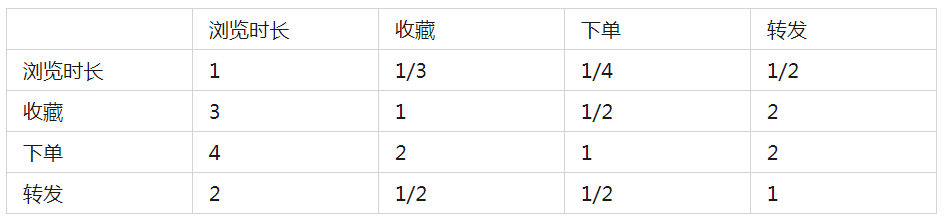
將上述矩陣進行歸一化、計算權重后,最終計算的權重結果如下圖所示:

瀏覽:0.1,收藏:0.29;下單:0.43;轉發:0.18。一致性檢驗過程如下圖所示:CR=0.02<0.1 一致性檢驗通過

最終確定標準化指標,如下表:
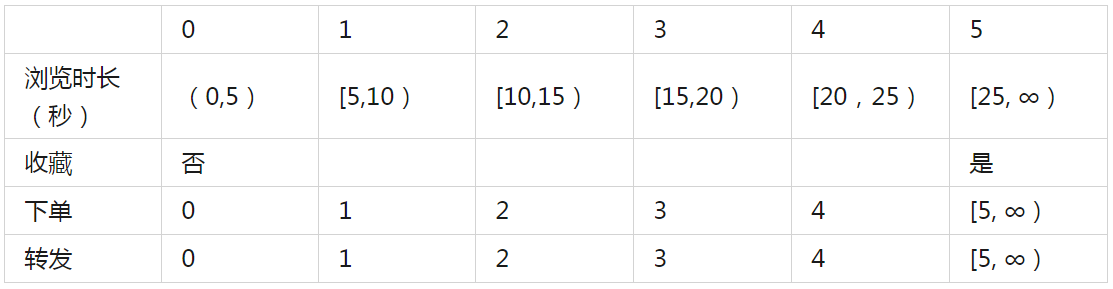
3.1.3 構建用戶對物品的喜愛度矩陣
根據上述計算過程,可以計算用戶對某物品的喜愛度。
例如用戶1,對物品a:瀏覽了13S,未收藏,下單了1次,轉發了2次,則用戶1對物品a的喜愛度為:2*0.1+0*0.29+1*0.43+2*0.18,最終計算所有用戶對物品的喜愛度矩陣:
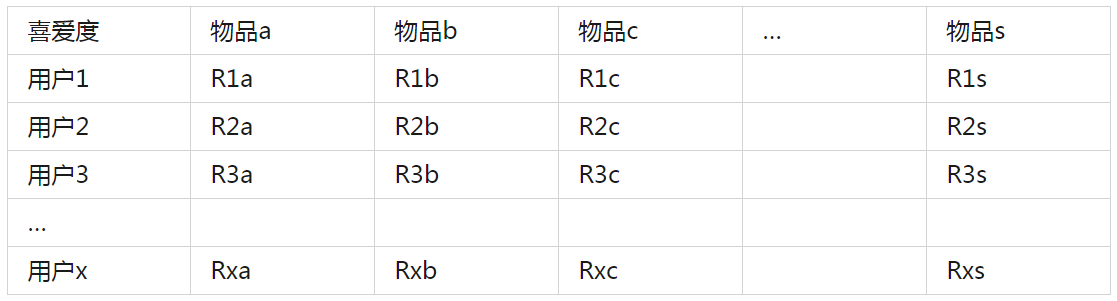
3.1.4 構建物品對物品的相似度矩陣S
按照喜愛度矩陣R,根據皮爾遜相關系數公式(兩個變量之間的皮爾遜相關系數定義為兩個變量之間的協方差和標準差的商),可計算出多個物品之間的相似度:
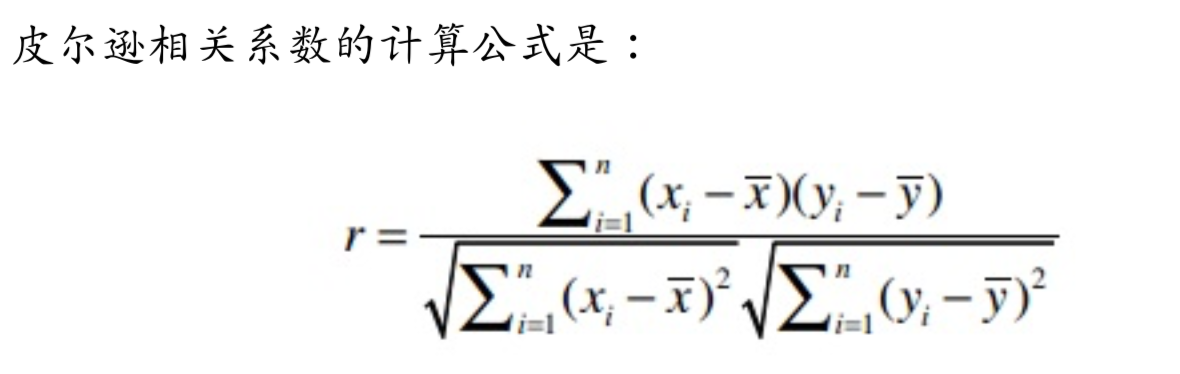
- Xi:用戶i對物品X的喜愛度
- `X:所有用戶對物品X的喜愛度的算數平均值
- Yi:用戶i對物品Y的喜愛度
- `Y:所有用戶對物品Y的喜愛度的算數平均值
- r: 物品x和物品y的相似度
最終可計算出相似度矩陣S,矩陣為對稱矩陣:
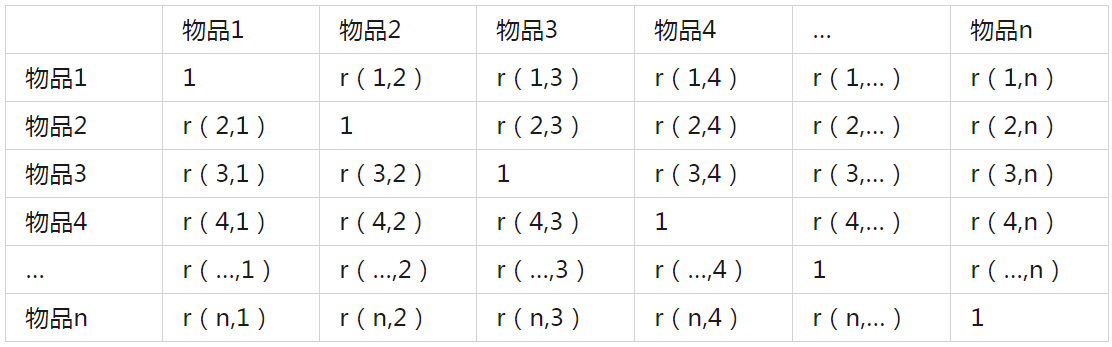
3.1.5 預測用戶A對物品b的喜好
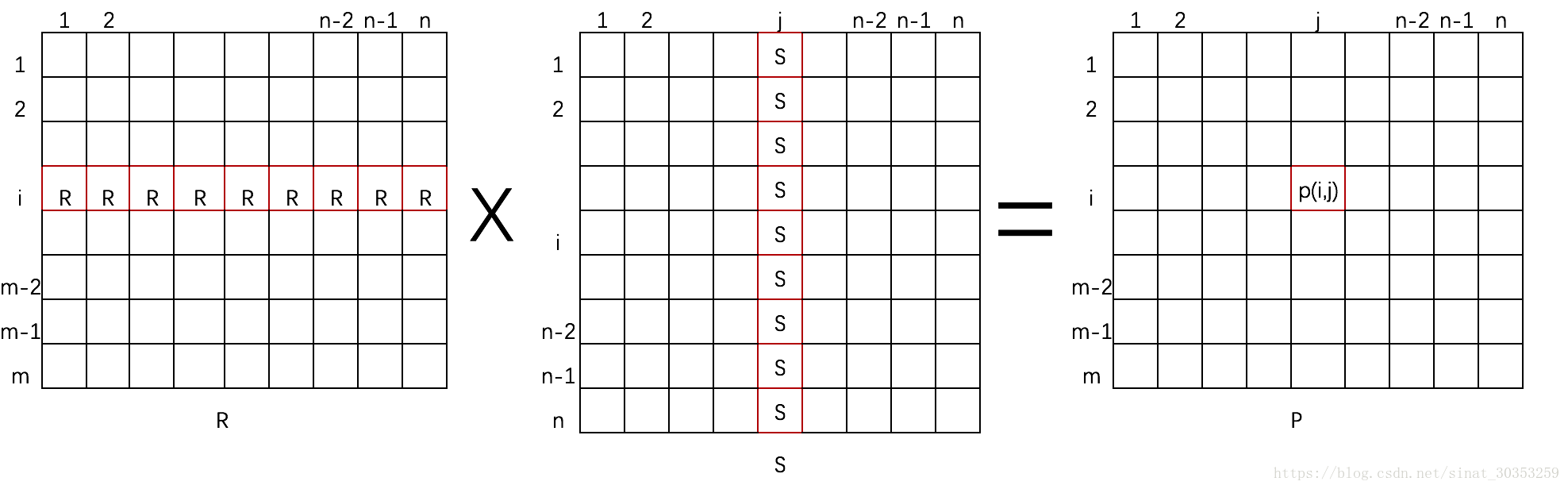
通過喜好矩陣R*相似度矩陣S,即用戶i對所有物品的評分作為權重,和物品j中的物品相似度乘積加和,可得到用戶i對物品j的評分預測P(i,j)。
3.2 基于用戶的協同過濾
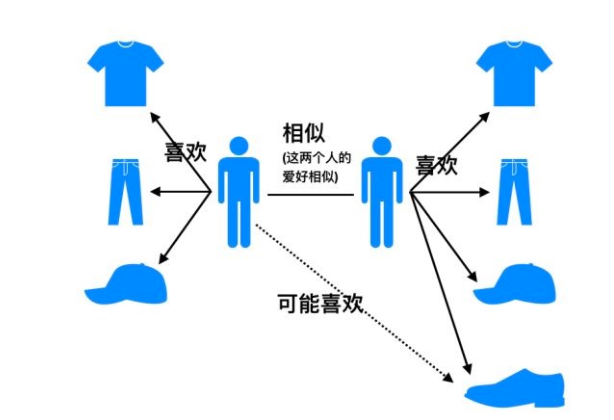
基于用戶的協同推薦算法認為: 當用戶A喜歡物品a,且用戶A和用戶B相似,則認為用戶B喜歡物品a。
所以搭建該算法分為兩步:
- 計算用戶A對物品a的喜愛度
- 計算用戶A和用戶B的相似度
用戶B對物品a的喜好矩陣=用戶A對物品a的喜好矩陣+用戶A和用戶B的相似度,計算過程和基于物品的協同過濾的極端過程基本一致。
4. 推薦效果驗證
在推薦系統上線前的離線測試、 AB測試階段,需要系統的驗證推薦系統的效果。
推薦系統推薦給用戶的東西有多少是用戶真正喜歡的、帶來了多大的轉化率等等。驗證推薦系統的效果常見的指標,包括:
- 準確度
- 召回率
- 覆蓋率
- 多樣性
4.1 準確率
準確率表示預測為正的樣本中,真正的正樣本的比例。
公式如下:
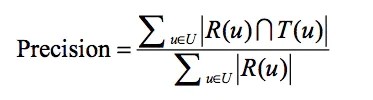
R(u)是根據用戶在訓練集上的行為給用戶作出的推薦列表,而T(u)是用戶在測試集上的行為列表。
最簡單的例子:例如推薦系統給用戶推薦了10件物品,用戶進入物品詳情頁定義為判斷真正的正樣本的行為,用戶進入了其中3件物品的詳情頁,則此時準確率=3/10=30%。
4.2 召回率
召回率表示的是真正的正樣本中,被推薦的真正的正樣本的比例。
公式如下:
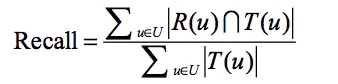
R(u)是根據用戶在訓練集上的行為給用戶作出的推薦列表,而T(u)是用戶在測試集上的行為列表。
最簡單的例子:用戶進入物品詳情頁定義為判斷真正的正樣本的行為,用戶進入了20件物品的詳情頁,其中3件物品是從推薦列表中進入的,則此時準確率=3/20=15%。
4.3 覆蓋率
覆蓋率表示的是被推薦出來的樣本,占總樣本的比例。
公式如下:
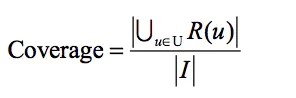
U是推薦系統中所有用戶的集合,R(u)是給每個用戶推薦的物品列表,I是所有推薦池的物品。最簡單的例子:給用戶推薦了10件商品,總共100件商品,則此時覆蓋率=10/100=10%。
4.4 多樣性
多樣性表示被推薦的物品,兩兩之間的差異性。
公式如下:
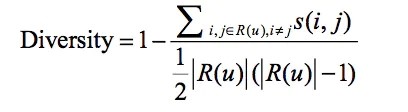
s(i, j)是推薦的物品i和j之間的相似度,u是被推薦的用戶,R(u)是給用戶推薦的物品列表。
4.5 其他指標
除了上述指標外,也有從其他業務維度驗證推薦系統效果的指標。例如新穎性、驚喜度、信任性、實時性、健壯性,以及基于公司發展規劃的商業指標等。
5. 總結
當公司業務/產品,發展到一定規模,積累了一定的數據量,為了進一步提升業務指標/用戶體驗,往往會考慮個性化推薦系統。
從0搭建mvp的個性化推薦系統,需要:
- 梳理數據源,維護底層數據質量、拓展數據維度;
- 基于對業務的深入理解,形成符合業務需求的推薦模型;
- 最終形成給用戶的個性化推薦功能。
個性化推薦系統,最常見的就是基于用戶/基于物品的協同過濾。構建協同過濾模型,需要:
- 計算用戶-物品的喜愛度矩陣R;
- 計算用戶-用戶/物品-物品的相似度矩陣S;
- 兩個矩陣相乘,得到用戶-物品的喜愛度預測值。根據預測值進行推薦;
- 驗證推薦效果,并持續調優。
另外,在從0搭建推薦系統,開需要考慮用戶冷啟動、物品冷啟動等問題。
?
本文由 @16哥 原創發布于人人都是產品經理,未經許可,禁止轉載。
題圖來自 Pexels,基于 CC0 協議
本文被轉載2次
首發媒體 | 轉發媒體
| 轉發媒體

















