芯動(dòng)力RPP架構(gòu)成功適配微軟BitNet,打造端側(cè)AI高效推理新生態(tài)
BitNet為邊緣AI的加速普及帶來(lái)新活力。
微軟開(kāi)源BitNet模型結(jié)合芯動(dòng)力RPP生態(tài)架構(gòu),可在邊緣和端側(cè)智能設(shè)備上快速適配和部署新的模型,為邊緣AI的加速普及帶來(lái)新的活力。
【內(nèi)容目錄】
1.什么是BitNet?
2.BitNet的優(yōu)勢(shì)何在?
3.國(guó)外企業(yè)在BitNet與硬件適配方面的具體實(shí)踐
4.國(guó)內(nèi)廠商基于BitNet架構(gòu)的“端側(cè)AI”模型輕量化嘗試
5.BitNet模型與新興具身機(jī)器人應(yīng)用
6.BitNet有望引爆 家電 、 汽車(chē) 和 手機(jī) 市場(chǎng)
7.結(jié)語(yǔ)
01.
什么是BitNet?
最近微軟發(fā)布了首個(gè)開(kāi)源的“原生1bit”LLM -- BitNet b1.58 2B4T,參數(shù)規(guī)模達(dá)到20億,訓(xùn)練數(shù)據(jù)高達(dá)4萬(wàn)億token,從根本上重構(gòu)了AI的計(jì)算引擎。它用超高效的加法運(yùn)算,取代了AI模型中最昂貴的浮點(diǎn)乘法運(yùn)算。
傳統(tǒng)LLM(如GPT系列)依賴于高精度的16位或32位浮點(diǎn)數(shù),或低精度的8位及4位整數(shù),來(lái)表示模型中的“權(quán)重”,而B(niǎo)itNet則采取了一種更為激進(jìn)的三元表達(dá)方法。BitNet模型中的每一個(gè)權(quán)重都只能是如下三個(gè)值之一:-1、0 或 +1,即在訓(xùn)練的時(shí)候就是訓(xùn)練為-1,0,1,所以在推理的時(shí)候沒(méi)有精度損失。
這種設(shè)計(jì)被稱為三元量化(Ternary Quantization),因?yàn)樗褂昧舜蠹s1.58個(gè)比特(log 2(3)≈1.58)的信息來(lái)存儲(chǔ)每個(gè)權(quán)重,最終效果并不比高精度方法差。
實(shí)現(xiàn)這一目標(biāo)的核心是其創(chuàng)新的BitLinear層。在標(biāo)準(zhǔn)的Transformer模型(現(xiàn)今大多數(shù)LLM的基礎(chǔ)架構(gòu))中,矩陣乘法是計(jì)算的核心和瓶頸。BitLinear層用更高效的加法和減法取代了這些昂貴的乘法運(yùn)算,因?yàn)閷?duì)-1、0、1的操作本質(zhì)上就是加減法。
重要的是,BitNet模型是從零開(kāi)始就使用這種三進(jìn)制方式進(jìn)行訓(xùn)練的,即量化感知訓(xùn)練(Quantization-Aware Training, QAT),這使得模型能夠在低比特的限制下依然保持高性能,而非簡(jiǎn)單地對(duì)已訓(xùn)練好的模型進(jìn)行壓縮。
02.
BitNet的優(yōu)勢(shì)何在?
BitNet的革命性并非空談,其優(yōu)勢(shì)直指當(dāng)前AI發(fā)展面臨的核心痛點(diǎn):巨大的計(jì)算資源消耗和高昂的成本。其優(yōu)勢(shì)表現(xiàn)在:
1. 極致的效率和成本效益:
? ?內(nèi)存占用大幅降低:由于每個(gè)權(quán)重僅需約1.58位,相比于16位浮點(diǎn)數(shù),BitNet可以將模型的內(nèi)存占用降低約10倍。這意味著,過(guò)去需要龐大數(shù)據(jù)中心才能運(yùn)行的大型模型,未來(lái)也許可以直接在個(gè)人電腦甚至智能手機(jī)上流暢運(yùn)行。
? 計(jì)算速度顯著提升:用加減法替代乘法,極大地簡(jiǎn)化了計(jì)算過(guò)程。這不僅意味著更快的推理速度,也使得通過(guò)邊緣設(shè)備的CPU+NPU計(jì)算組合高效運(yùn)行LLM成為可能,擺脫了對(duì)昂貴且稀缺的GPU芯片的依賴。
? 能耗大幅下降:更簡(jiǎn)單的計(jì)算和更小的模型尺寸直接帶來(lái)了能耗的顯著降低。這使得在筆記本電腦、智能汽車(chē)、物聯(lián)網(wǎng)設(shè)備等對(duì)功耗敏感的邊緣設(shè)備上部署強(qiáng)大AI成為現(xiàn)實(shí),同時(shí)也響應(yīng)了全球?qū)G色計(jì)算和可持續(xù)發(fā)展的呼吁。
下面的圖表是BitNet與Llama大模型在存儲(chǔ)要求和解碼性能方面的對(duì)比。

2. 保持高性能: 令人驚訝的是,這種極致的壓縮并沒(méi)有以犧牲性能為代價(jià)。微軟的研究表明,在一定模型規(guī)模(例如30億參數(shù))以上,BitNet b1.58模型的性能(如困惑度和下游任務(wù)表現(xiàn))可以媲美甚至超過(guò)同等規(guī)模的半精度(FP16)模型,這打破了“模型越大且精度越高,性能才越強(qiáng)”的傳統(tǒng)認(rèn)知。
下圖是BitNet與目前主流模型的參數(shù)性能對(duì)比。

可以看出,BitNet并非要完全取代Transformer架構(gòu),而是對(duì)其核心計(jì)算方式的一次“魔改”。它保留了Transformer強(qiáng)大的結(jié)構(gòu)和能力,但通過(guò)釜底抽薪的方式解決了其效率和成本問(wèn)題。
03.
國(guó)外企業(yè)在 BitNet與硬件適配
方面的具體實(shí)踐
盡管微軟的BitNet技術(shù)在AI社區(qū)引起了不小的反響,但截至目前,國(guó)外大型電子硬件公司(如 蘋(píng)果 、三星、高通等)尚未公開(kāi)發(fā)布任何已將BitNet直接集成到其產(chǎn)品中的具體實(shí)踐或合作項(xiàng)目。
然而,這并不意味著適配工作沒(méi)有在進(jìn)行中。由于BitNet技術(shù)還非常新,相關(guān)的實(shí)踐目前更多地體現(xiàn)在社區(qū)驅(qū)動(dòng)的實(shí)驗(yàn)、性能基準(zhǔn)測(cè)試以及為未來(lái)適配鋪路的軟件框架上。以下是當(dāng)前國(guó)外企業(yè)和開(kāi)發(fā)者社區(qū)在BitNet與 智能硬件 適配方面的主要?jiǎng)討B(tài):

1. 核心推動(dòng)力:bitnet.cpp框架
微軟官方開(kāi)源的bitnet.cpp是推動(dòng)BitNet走向智能硬件的關(guān)鍵。它是一個(gè)專門(mén)為1-bit LLM設(shè)計(jì)、高度優(yōu)化的推理框架。
? 專為CPU設(shè)計(jì):bitnet.cpp的核心優(yōu)勢(shì)在于它可以在沒(méi)有昂貴GPU的情況下,高效地在CPU上運(yùn)行。這直接契合了絕大多數(shù)電子產(chǎn)品(如智能手機(jī)、筆記本電腦、物聯(lián)網(wǎng)設(shè)備)的硬件配置。
? 跨平臺(tái)支持:該框架支持在主流的x86架構(gòu)(如英特爾、AMD處理器)和Arm架構(gòu)上運(yùn)行。Arm架構(gòu)是幾乎所有智能手機(jī)和眾多平板電腦、邊緣設(shè)備的核心,因此bitnet.cpp的Arm優(yōu)化是其在智能終端領(lǐng)域應(yīng)用的基礎(chǔ)。
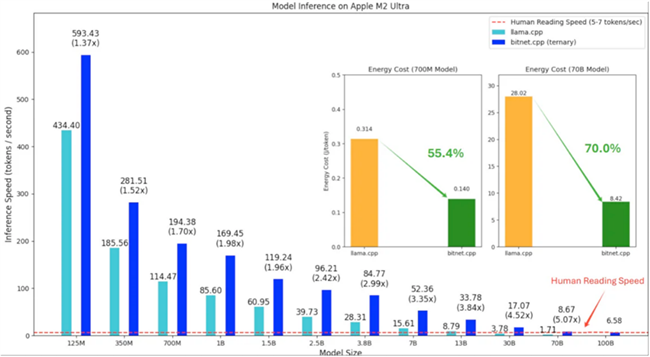
2. 在Arm硬件上的性能表現(xiàn)
根據(jù)微軟官方測(cè)試數(shù)據(jù),已有的基準(zhǔn)測(cè)試展示了BitNet在常用硬件上的巨大潛力:
? 顯著的速度提升:在ARM CPU(如蘋(píng)果的M系列芯片)上,使用bitnet.cpp運(yùn)行BitNet模型,相比于傳統(tǒng)的16位浮點(diǎn)模型(fp16),速度有1.37倍到5.07倍的提升,且模型越大,加速效果越明顯。
? 驚人的能效:在能耗方面,bitnet.cpp在Arm CPU上的表現(xiàn)同樣出色,能夠?qū)⒛芎慕档?5%到70%。這對(duì)于依賴電池供電的移動(dòng)設(shè)備來(lái)說(shuō)是至關(guān)重要的優(yōu)勢(shì)。
? 實(shí)現(xiàn)“不可能的任務(wù)”:測(cè)試表明,bitnet.cpp甚至可以在單個(gè)CPU上運(yùn)行高達(dá)1000億參數(shù)的BitNet模型,其速度足以達(dá)到人類的正常閱讀水平(約每秒5-7個(gè)詞元)。這在過(guò)去是無(wú)法想象的,它意味著未來(lái)極其強(qiáng)大的AI模型或許可以直接在用戶的個(gè)人設(shè)備上本地運(yùn)行。
3. 潛在的應(yīng)用場(chǎng)景與廠商的興趣點(diǎn)
盡管沒(méi)有官宣合作,但可以預(yù)見(jiàn),智能硬件廠商正密切關(guān)注BitNet,原因在于:
? 打造真正的端側(cè)AI:智能硬件廠商們(如蘋(píng)果、谷歌、三星)一直致力于將更多AI功能本地化,以提升響應(yīng)速度、保護(hù)用戶隱私并降低對(duì)云服務(wù)的依賴。BitNet的輕量化和高效性使其成為實(shí)現(xiàn)這一目標(biāo)的理想技術(shù)。
? 降低成本和功耗:在競(jìng)爭(zhēng)激烈的消費(fèi)電子市場(chǎng),任何能夠降低硬件成本和延長(zhǎng)電池續(xù)航的技術(shù)都極具吸引力。BitNet無(wú)需高端GPU,并能顯著降低能耗,這完美契合了廠商的需求。
? 催生新的智能體驗(yàn):通過(guò)在設(shè)備上本地運(yùn)行強(qiáng)大的語(yǔ)言模型,可以實(shí)現(xiàn)更智能、更無(wú)縫的交互體驗(yàn),例如更自然的語(yǔ)音助手、離線的實(shí)時(shí)翻譯、設(shè)備端的文檔摘要和內(nèi)容創(chuàng)作等。
目前,BitNet與消費(fèi)電子硬件的適配尚處于“黎明前夜”。雖然我們還沒(méi)有看到支持BitNet架構(gòu)的手機(jī)或筆記本電腦上市,但所有的基礎(chǔ)工作都在迅速推進(jìn)。開(kāi)發(fā)者社區(qū)和研究人員正在利用bitnet.cpp等工具,在現(xiàn)有的Arm和x86硬件上不斷進(jìn)行測(cè)試和優(yōu)化,驗(yàn)證其可行性和巨大優(yōu)勢(shì)。
可以預(yù)見(jiàn),隨著技術(shù)的成熟和相關(guān)工具鏈的完善,未來(lái)一到兩年內(nèi),我們很有可能會(huì)看到一些領(lǐng)先的硬件廠商宣布與微軟合作,或推出專為運(yùn)行此類1-bit模型而優(yōu)化的芯片或硬件解決方案。
04.
國(guó)內(nèi)廠商基于 BitNet架構(gòu)的
“端側(cè)AI”模型輕量化嘗試
雖然目前還沒(méi)有知名的國(guó)內(nèi)終端廠商官宣支持BitNet,但所有頭部廠商都認(rèn)識(shí)到,將AI能力從云端下放到手機(jī)、PC、汽車(chē)等邊緣和終端電子設(shè)備上,是提升用戶體驗(yàn)、保護(hù)數(shù)據(jù)隱私和構(gòu)建技術(shù)護(hù)城河的關(guān)鍵。
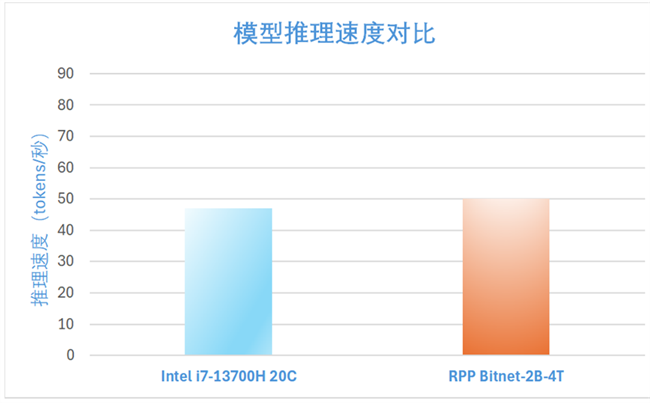
據(jù)筆者了解,邊緣AI芯片廠商芯動(dòng)力是目前國(guó)內(nèi)唯一在嘗試適配BitNet模型的企業(yè)。芯動(dòng)力已經(jīng)成功實(shí)現(xiàn)業(yè)界首家微軟BitNet大語(yǔ)言模型的本地化高效適配,其自主研發(fā)的RPP架構(gòu)完美支持BitNet-b1.58-2B-4T模型推理。

在適配過(guò)程中,芯動(dòng)力技術(shù)團(tuán)隊(duì)采用了微軟官方推薦的I2_S編碼方式,確保模型性能的充分發(fā)揮。值得一提的是,該方案在聯(lián)想ThinkPad 16p Gen6這款革命性AI PC上展現(xiàn)出卓越的推理能力——作為全球首款搭載dNPU專用AI加速芯片的筆記本電腦,其內(nèi)置的RPP dNPU加速卡為大型語(yǔ)言模型的高效運(yùn)行提供了硬件級(jí)保障。
性能測(cè)試數(shù)據(jù)表明,芯動(dòng)力RPP的推理效率已超越微軟官方公布的基準(zhǔn)表現(xiàn),這標(biāo)志著國(guó)產(chǎn)AI加速技術(shù)在邊緣計(jì)算領(lǐng)域取得重大突破,為下一代智能終端的AI應(yīng)用普及奠定了堅(jiān)實(shí)基礎(chǔ)。
可以預(yù)見(jiàn),隨著B(niǎo)itNet及其背后的1-bit LLM技術(shù)被證明其價(jià)值,國(guó)內(nèi)廠商很可能會(huì)迅速吸收這些先進(jìn)理念,并將其融入到自家的技術(shù)體系中,甚至與芯片合作伙伴共同推出專門(mén)針對(duì)此類超低比特模型進(jìn)行優(yōu)化的硬件,從而在這場(chǎng)全球性的AI效率革命中占據(jù)有利位置。
05.
BitNet模型與新興具身機(jī)器人應(yīng)用
BitNet模型與具身機(jī)器人的結(jié)合,代表了低功耗AI與物理智能體融合的前沿方向,下面從技術(shù)協(xié)同、應(yīng)用場(chǎng)景、產(chǎn)業(yè)生態(tài)及未來(lái)挑戰(zhàn)四個(gè)維度來(lái)簡(jiǎn)要分析一下其發(fā)展前景:
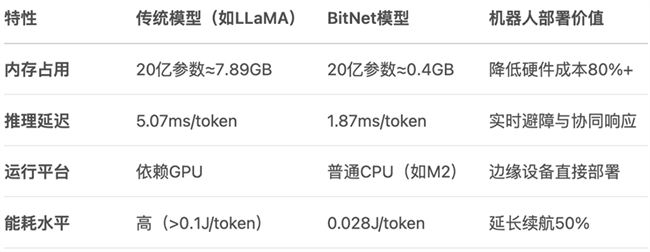
技術(shù)協(xié)同: 低精度計(jì)算與機(jī)器人硬件的深度適配。BitNet的核心優(yōu)勢(shì)在于超低內(nèi)存資源消耗、處理器(CPU+NPU)友好性及實(shí)時(shí)響應(yīng)能力,可滿足具身機(jī)器人對(duì)本地化部署、計(jì)算處理能力與能耗的最優(yōu)化、物理空間的量化理解,以及動(dòng)態(tài)環(huán)境的毫秒級(jí)決策等要求。
應(yīng)用場(chǎng)景: 從工業(yè)到消費(fèi)領(lǐng)域的規(guī)模化滲透。BitNet支持輕量級(jí)端到端控制,可靈活適配AGV、裝配機(jī)械臂等工業(yè)自動(dòng)化設(shè)備。在消費(fèi)與服務(wù)領(lǐng)域,BitNet可協(xié)助小型化設(shè)備(如掃地機(jī)器人、陪護(hù)機(jī)器人)實(shí)現(xiàn)復(fù)雜指令理解與環(huán)境交互,解決傳統(tǒng)終端算力瓶頸問(wèn)題。
產(chǎn)業(yè)生態(tài): 硬件-軟件協(xié)同創(chuàng)新。bitnet.cpp框架可為BitNet提供底層加速,未來(lái)可以拓展至ROS等機(jī)器人操作系統(tǒng)。基于Arm或RISC-V的異構(gòu)計(jì)算架構(gòu)(CPU+NPU)芯片,像芯動(dòng)力的RPP,可以適配BitNet量化計(jì)算,極大提升能效比。
未來(lái)挑戰(zhàn): BitNet依賴微軟專用框架(bitnet.cpp),尚未兼容PyTorch生態(tài),制約開(kāi)發(fā)者生態(tài)擴(kuò)展。其1.58位量化方法在訓(xùn)練時(shí)可能比較復(fù)雜,耗時(shí)較長(zhǎng),會(huì)削弱復(fù)雜場(chǎng)景推理能力(如多物體動(dòng)態(tài)交互),需與RoboBrain 2.0等空間模型融合補(bǔ)償。此外,現(xiàn)有機(jī)器人關(guān)節(jié)模組(如滾柱絲杠、力矩電機(jī))能耗仍高,需與AI能效提升同步優(yōu)化。
未來(lái)突破路徑包括模型輕量化--擴(kuò)展BitNet至多模態(tài)輸入(視覺(jué)+力控);開(kāi)源生態(tài)--推動(dòng)BitNet接入ROS 2.0或鴻蒙系統(tǒng),吸引開(kāi)發(fā)者社區(qū);算力-執(zhí)行器協(xié)同:結(jié)合諧波減速器、力矩傳感器等硬件創(chuàng)新,打造高能效機(jī)器人關(guān)節(jié)。
06.
BitNet有望引爆家電、汽車(chē)和手機(jī)市場(chǎng)
當(dāng)強(qiáng)大的AI能力可以被低成本、高效率地嵌入到每一個(gè)硬件設(shè)備中時(shí),它不但可以降低計(jì)算成本,提升智能設(shè)備能效比,甚至將徹底顛覆現(xiàn)有產(chǎn)業(yè)的形態(tài)和價(jià)值鏈。
1. 手機(jī)產(chǎn)業(yè):從“智能手機(jī)”到“AI手機(jī)”的終極躍遷
? 現(xiàn)狀:目前的手機(jī)AI多是“偽端側(cè)”,許多功能仍需聯(lián)網(wǎng)調(diào)用云端API。
? BitNet帶來(lái)的未來(lái):
超級(jí)個(gè)人助理:手機(jī)可以本地運(yùn)行一個(gè)真正懂你的、擁有長(zhǎng)期記憶的AI助理,它了解你的所有習(xí)慣和信息(因?yàn)閿?shù)據(jù)不出本地),能主動(dòng)為你規(guī)劃日程、管理信息、提供建議。
永不掉線的實(shí)時(shí)功能:無(wú)論在飛機(jī)上還是地下室,實(shí)時(shí)翻譯、文檔摘要、圖像處理等功能都能瞬時(shí)完成。
極致個(gè)性化:AI可以根據(jù)你的使用習(xí)慣,實(shí)時(shí)、動(dòng)態(tài)地優(yōu)化手機(jī)的性能、功耗和用戶界面,成為獨(dú)一無(wú)二的“個(gè)性化手機(jī)”。
2. 汽車(chē)產(chǎn)業(yè):加速邁向真正的“智能座艙”與“自動(dòng)駕駛”
? 現(xiàn)狀:智能汽車(chē)對(duì)網(wǎng)絡(luò)和云端算力高度依賴,自動(dòng)駕駛的決策延遲和安全性是巨大挑戰(zhàn)。
? BitNet帶來(lái)的未來(lái):
瞬時(shí)決策的自動(dòng)駕駛:復(fù)雜的環(huán)境感知和駕駛決策模型可以在車(chē)內(nèi)本地完成,擺脫網(wǎng)絡(luò)延遲,極大地提升自動(dòng)駕駛的安全性與可靠性。
會(huì)思考的智能座艙:車(chē)載語(yǔ)音助手不再是機(jī)械的“命令執(zhí)行者”,而是能理解復(fù)雜語(yǔ)境、結(jié)合車(chē)輛狀態(tài)和外部環(huán)境進(jìn)行多輪自然對(duì)話的“智能副駕”。
隱私保護(hù):車(chē)輛的行駛軌跡、車(chē)內(nèi)對(duì)話等敏感數(shù)據(jù)都無(wú)需上傳云端,最大程度保護(hù)用戶隱私。
3. 家電產(chǎn)業(yè):從“功能性產(chǎn)品”到“有智慧的家庭成員”
? 現(xiàn)狀:智能家居依然停留在“手機(jī)App控制”或簡(jiǎn)單的語(yǔ)音指令階段,設(shè)備間聯(lián)動(dòng)生硬,并不“智能”。
? BitNet帶來(lái)的未來(lái):
主動(dòng)服務(wù)的家電:你的空調(diào)會(huì)根據(jù)你的睡眠狀態(tài)、室外天氣和你的體感習(xí)慣,主動(dòng)調(diào)節(jié)到最舒適的溫度;你的冰箱能根據(jù)現(xiàn)有食材,主動(dòng)為你生成菜譜并聯(lián)動(dòng)烤箱設(shè)置程序。
無(wú)處不在的自然交互:你不再需要尋找手機(jī)或智能音箱,可以直接對(duì)任何家電用自然語(yǔ)言下達(dá)指令,甚至通過(guò)一個(gè)眼神、一個(gè)手勢(shì)與之交互。
真正的智能家庭中樞:所有家電擁有了本地的“大腦”,它們可以協(xié)同工作,形成一個(gè)統(tǒng)一的、無(wú)需云端協(xié)調(diào)的智能網(wǎng)絡(luò),真正實(shí)現(xiàn)“全屋智能”。
07.
結(jié)語(yǔ)
微軟提出的BitNet框架為邊緣AI的加速普及帶來(lái)了新的活力,也為中國(guó)企業(yè)提供了一個(gè)在AI應(yīng)用領(lǐng)域“換道超車(chē)”的絕佳機(jī)會(huì)。智能硬件成為AI的最佳載體,而中國(guó)強(qiáng)大的設(shè)計(jì)制造和軟硬件整合能力,將成為AI發(fā)展的核心優(yōu)勢(shì)。
類似BitNet的模型將會(huì)如雨后春筍一樣出現(xiàn),而這對(duì)于硬件的靈活性要求極高,像芯動(dòng)力的RPP架構(gòu)不但兼容CUDA生態(tài),而且可快速適配和部署新的模型,及時(shí)獲取生態(tài)開(kāi)發(fā)者反饋并快速迭代,從而加速AI在邊緣和端側(cè)的普及。



